The cache tutorial¶
Main idea¶
One of the most intriguing features of Quaterion is the caching mechanism. A tool which can make experimenting blazing fast.
During fine-tuning, you use a pre-trained model and attach one or more layers on top of it. The most resource-intensive part of this setup is inferring through the pre-trained layers. They usually have a vast amount of parameters.
However, in many cases, you don’t even want to update pre-trained weights. If you don’t have much data, it might be preferable to only tune the head layer to prevent over-fitting and catastrophic forgetting. Frozen layers do not require gradient calculation. Therefore you could perform training faster.
Quaterion, meanwhile, takes it one more step further.
In Quaterion, pre-trained models are used as encoders. If the encoder’s weights are frozen, then it is deterministic and emits the same embeddings for the same input every epoch. It opens a room for significant improvement - we can calculate these embeddings once and re-use them during training.
This is the main idea of the cache.
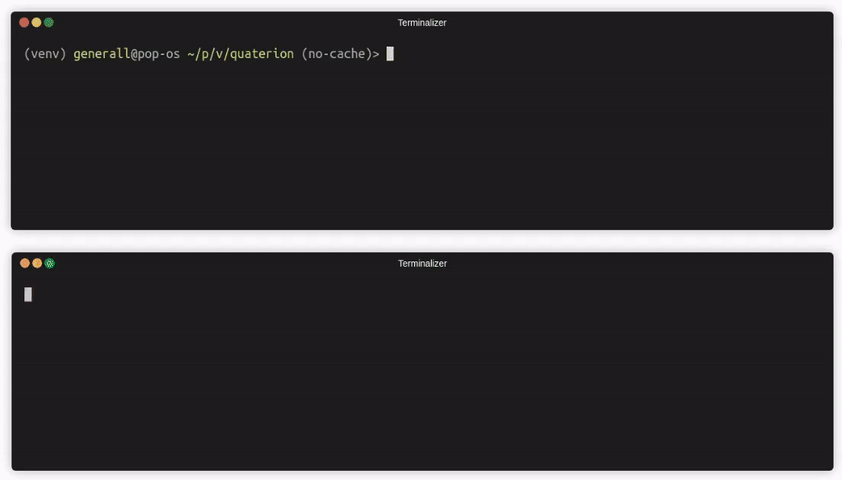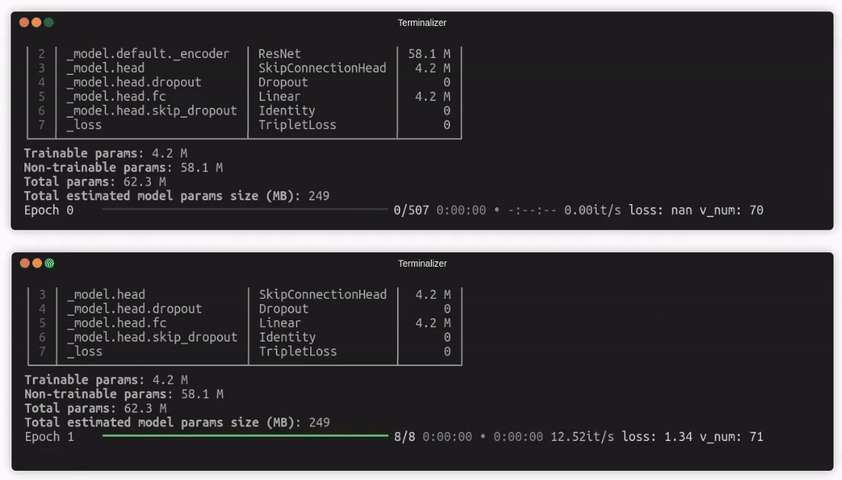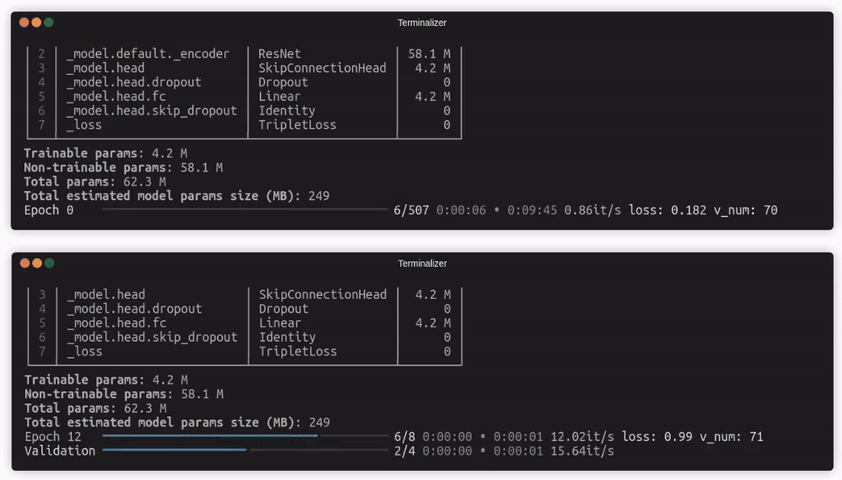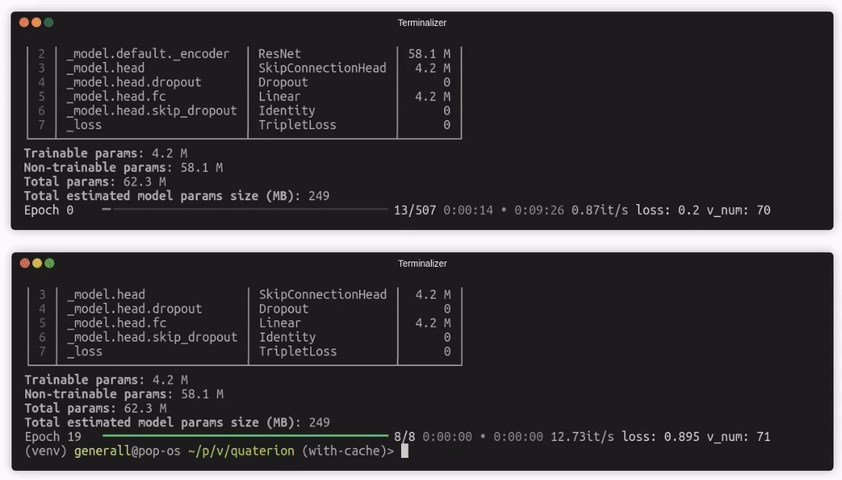
How to use it?¶
TrainableModel has configure_caches method which you need to override for cache usage.
This method should return CacheConfig instance containing cache settings.
def configure_caches(self) -> Optional[CacheConfig]:
return CacheConfig(...)
If the configuration is provided, Quaterion will perform a single pass through all datasets to populate the cache. After that, the trainer will use only cached embeddings. If you also provide the persistence parameters, the next run of the training will not require filling the cache.
Cache settings can be divided into parts according to their purpose:
Manage parameters of initial cache filling
Choose storage for embeddings
Customize how an object is cached
Options overview¶
The first part of the options includes batch_size and num_workers - these are directly passed to dataloader and used in the process of filling the cache.
batch_size - used for cached encoder inference and does not affect the training process.
Might be useful to adjust memory/speed balance.
num_workers determines the number of processes to be used during cache filling.
def configure_caches(self) -> Optional[CacheConfig]:
return CacheConfig(
batch_size=16,
num_workers=2
)
Storage settings are cache_type, mapping and save_dir.
The first two options configure the device to store the cached embeddings.
cache_type set a default storage type for all encoders which will be cached.
Currently, you can store your embeddings on CPU or on GPU.
mapping provides a way to define cache_type for each encoder separately.
The latter option, save_dir, sets up a directory on disk to store embeddings for subsequent runs.
If you don’t specify a directory for saving embeddings, Quaterion will populate the cache each time you start training.
def configure_caches(self) -> Optional[CacheConfig]:
return CacheConfig(
cache_type=CacheType.GPU, # GPU as a default storage for frozen encoders embeddings
mapping={"image_encoder": CacheType.CPU} # Store `image_encoder` embeddings on CPU
save_dir='cache'
)
The third part of the cache settings is aimed at advanced users and will be covered in Limitations.
Further optimizations¶
Despite eliminating the most time-consuming operations via cache, there may still be places that prevent your training loop from warp speed 🌀.
Dataset usually contains features and labels for training, and in a typical setup features are only used to create embeddings. If we already have all the embeddings, raw features are not actually required anymore. Moreover, reading the features from the disk can have significant I/O overhead and be a bottleneck during training.
A possible improvement here is to avoid reading the dataset and keep the labels during cache filling too. Quaterion will do it automatically and bring a noticeable increase in training speed if the cache is enabled and limitations described in the following chapter are met.
Limitations¶
There are several conditions required to use the cache:
At least one encoder should be frozen.
- Dataset should be the same on each epoch.
This unfortunately means that dynamic augmentations are not supported by the cache.
Dataset caching has more strict rules:
All encoders have to be frozen. If at least one is not, we can’t cache labels.
Multiprocessing is not allowed.
Key extraction is not overridden.
Multiprocessing¶
Cached labels are stored in an associated dataset instance. Therefore, this instance, and consequently the label cache, is bound to the process in which it was created. If we use multiprocessing, then the label cache is filled in a child process. We simply don’t have access to our label cache from the parent process during training, which makes it difficult to use multiprocessing in this case.
You can use num_workers=None in cache configuration to prevent multiprocessing during the cache population.
It is preferred to use a single process cache in case your training process is I/O bound.
For example, reading images from a disk could be a bottleneck in cached training.
But for NLP tasks having more CPU for pre-processing might be more influential than I/O speed.
Key extractor¶
The key extractor is the function used to get the key for the entry we want to store in the cache. By default, key_extractor uses the index of the item in the dataset as the cache key. This is usually sufficient, however, it has its drawbacks that you may want to avoid.
For instance, in some cases, data-independent keys may not be acceptable or desirable.
You can provide custom key_extractors and extract keys from features in your own way to obtain the desired behavior.
If you’re using a custom key extractor, you’ll need to access the features during training to get the key from it. But retrieving features from a dataset is exactly what we wanted to avoid when caching labels. Hence, usage of a custom key extractor makes label caching impossible.
def configure_caches(self) -> Optional[CacheConfig]:
def custom_key_extractor(feature):
return feature['filename'] # let's assume we have a dict as a feature
return CacheConfig(
key_extractor=custom_key_extractor # use feature's filename as a key
)
Comprehensive example¶
Now that we know about all the options and limitations of the cache, we can take a look at a more comprehensive example.
def configure_caches(self) -> Optional[CacheConfig]:
def custom_key_extractor(self, feature):
# let's assume that features is a row and its first 10 symbols uniquely determines it
return features[:10]
return CacheConfig(
mapping={
"content_encoder": CacheType.GPU,
# Store cache in GPU for `content_encoder`
"attitude_encoder": CacheType.CPU
# Store cache in RAM for `attitude_encoder`
},
batch_size=16,
save_dir='cache_dir', # directory on disk to store filled cache
num_workers=2, # Number of processes. Labels can't be cached if `num_workers` != 0
key_extractors=custom_key_extractor # Key extractor for each encoder.
# Equal to
# {
# "content_encoder": custom_key_extractor,
# "attitude_encoder": custom_key_extractor
# }
)
In this setup we have 2 encoders: content_encoder and attitude_encoder.
One of them stores its embeddings on the GPU, and the other on the CPU.
The cache is filled in batches of size 16.
After the cache is full, it will be stored in cache_dir under the current path.
The cache filling will be performed in two processes, and each encoder’s embeddings will be stored under a key extracted using custom_key_extractor.
The multiprocessing environment and the custom key extractor do not allow us to cache labels.
But with text data, it’s not that important to avoid I/O because strings aren’t as heavy as images and won’t incur much overhead.
More examples can be found at configure_caches documentation.
Full training pipeline utilising cache can be found in NLP tutorial.
